1
Systematically discovers capability gaps between models and produces interpretable weakness summaries, enabling a comprehensive understanding of model behavior.
Differences That Matter:
Auditing Models for Capability Gap Discovery and Rectification
| 1 Google | 2 Johns Hopkins University |
| [Paper] [BibTeX] |
but they rarely explain what changed, where it fails, or what’s still missing.
A framework that finds capability gaps and turns them into concrete fixes.
Systematically discovers capability gaps between models and produces interpretable weakness summaries, enabling a comprehensive understanding of model behavior.
Delivers actionable feedback that guides fixes and model improvement.
Abstract
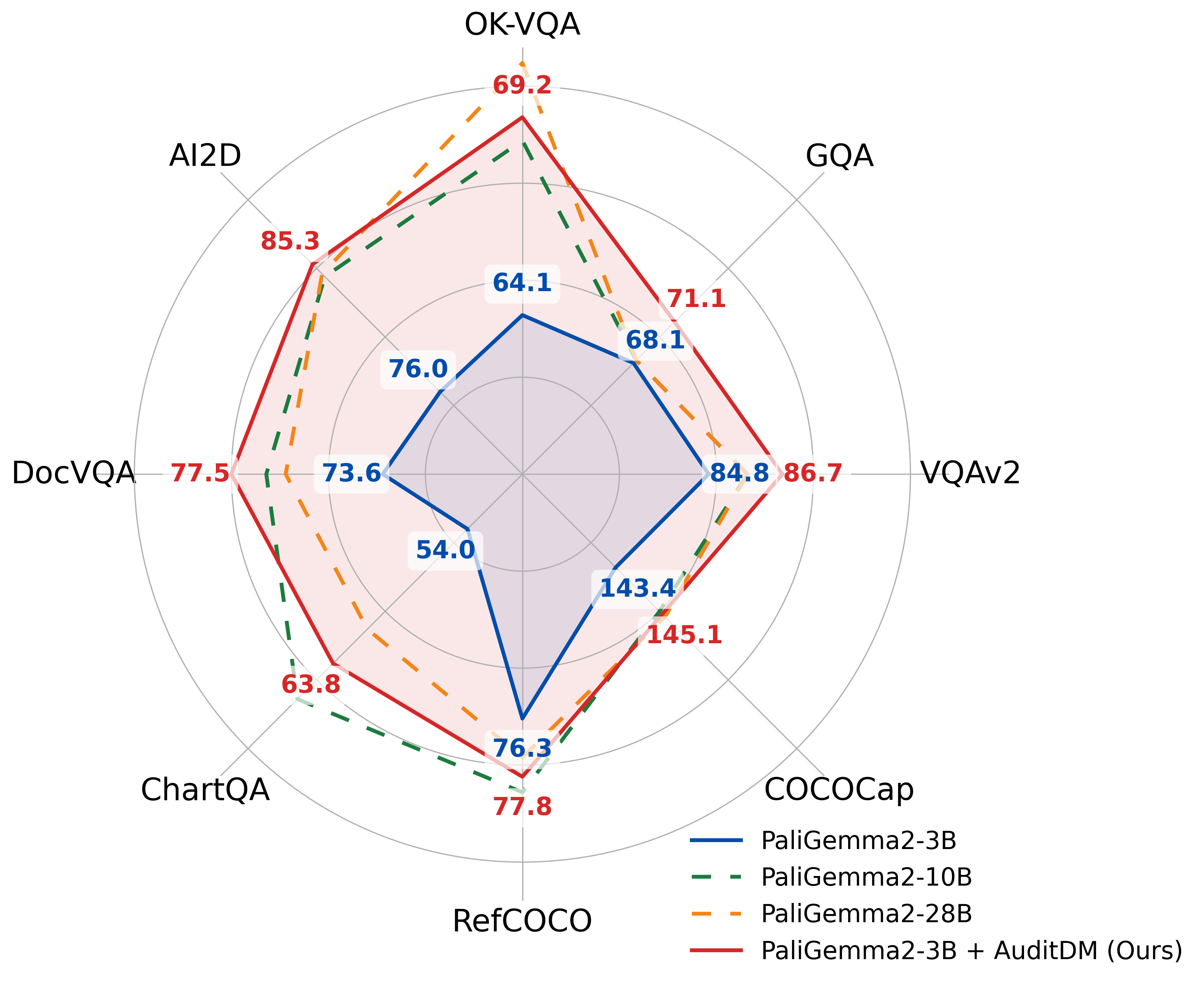
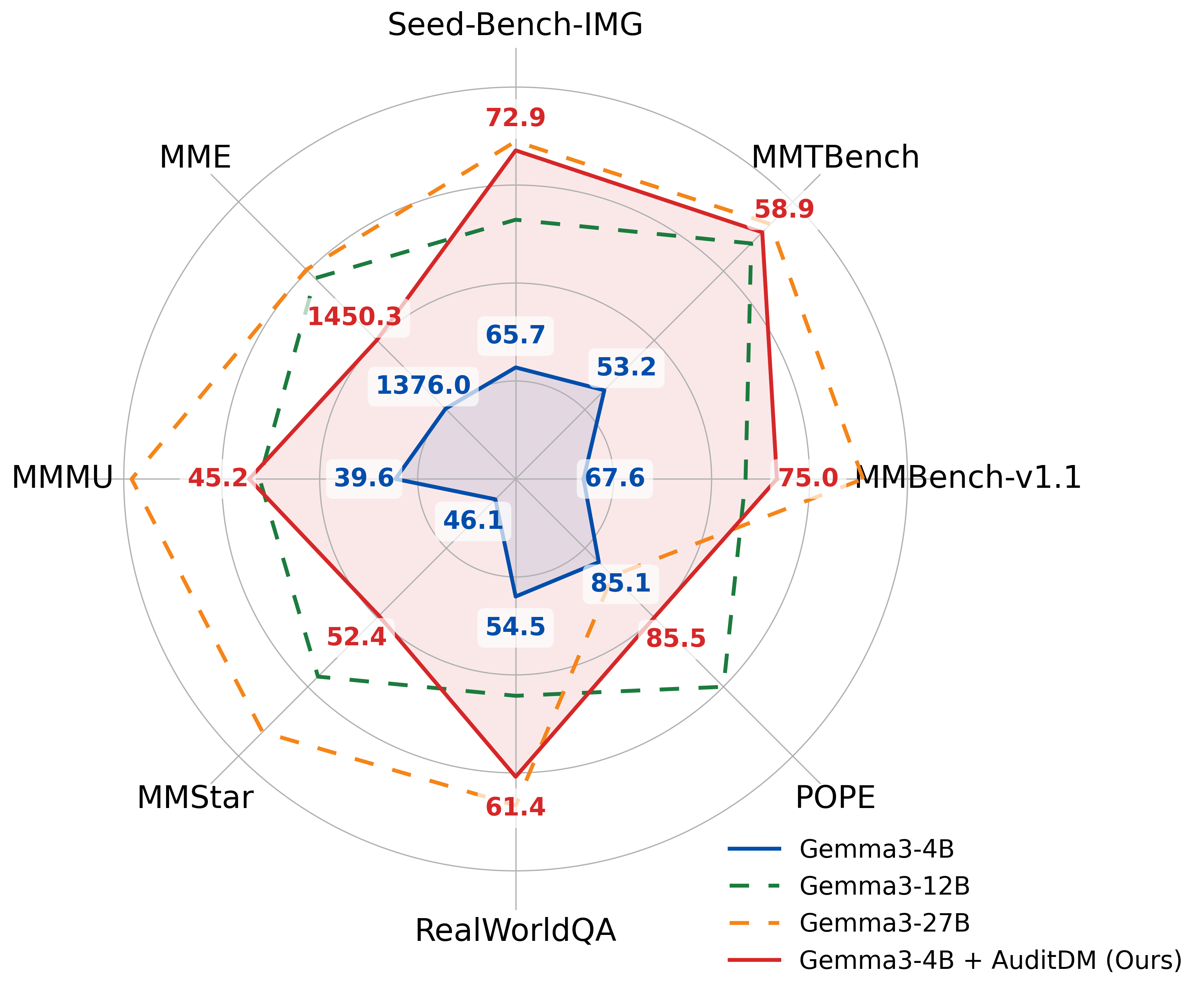
Conventional evaluation methods for multimodal LLMs (MLLMs) lack interpretability and are often insufficient to fully disclose significant capability gaps across models. To address this, we introduce AuditDM, an automated framework that actively discovers and rectifies MLLM failure modes by auditing their divergence. AuditDM fine-tunes an MLLM as an auditor via reinforcement learning to generate challenging questions and counterfactual images that maximize disagreement among target models. Once trained, the auditor uncovers diverse, interpretable exemplars that reveal model weaknesses and serve as annotation-free data for rectification. When applied to SoTA models like Gemma-3 and PaliGemma-2, AuditDM discovers more than 20 distinct failure types. Fine-tuning on these discoveries consistently improves all models across 16 benchmarks, and enables a 3B model to surpass its 28B counterpart. Our results suggest that as data scaling hits diminishing returns, targeted model auditing offers an effective path to model diagnosis and improvement.
Method
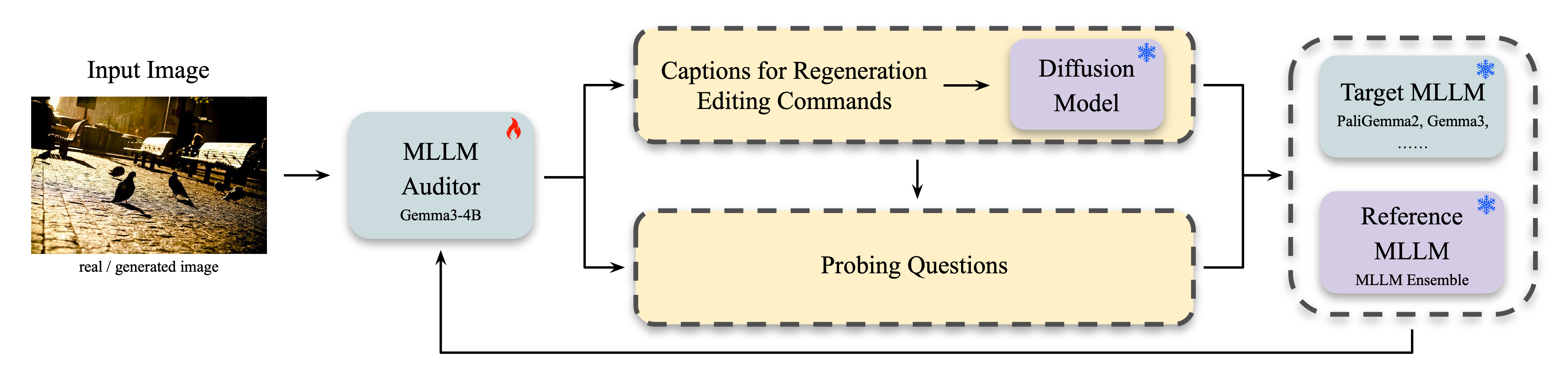
AuditDM fine-tunes an MLLM into an auditor that generates challenging probing questions and counterfactual images (via captions for image regeneration or editing commands), yielding question–image pairs on which the target model fails while the MLLM ensemble agrees, thus exposing capability gaps and failure modes. The auditor is trained to maximize prediction discrepancy between the target and the ensemble. Once trained, it identifies weaknesses and failure cases in a single inference pass.
AuditDM for Model Failure Detection
| AuditDM identifies the top 15 failure modes and challenging task categories for PaliGemma2-3B and 28B models at 448x448, and we report normalized per-category failure rates. Tasks are ordered left to right, beginning with the most pronounced weaknesses of the 3B model and progressing to those of the 28B. Notably, we observe that for certain tasks, the 28B model performs significantly worse than the 3B model. For example, on challenging images, the 28B model struggles more with color recognition and counting, and is more prone to hallucination |
| We provide examples generated by AuditDM for each failure category. To better demonstrate the effectiveness, we focus on examples with original images and generated questions in this figure. Image-question pairs with both generated images and questions are provided in the main paper. Some images are cropped or rotated for better figure layout. |
| AuditDM efficiently detects fine-grained visual cues that are irrelevant to the task/question yet still alter model predictions. We target PaliGemma2-28B (448x448) and showcase small modifications that fool the 28B model but not the 3B model, highlighting the effectiveness of our method in finding failures even in very powerful models. For each example, we show the original image (left), the modified image (right), and the corresponding answers. Our analysis shows that even the PaliGemma-2 28B model is highly sensitive to minor changes in task-irrelevant objects, suggesting that current MLLMs may still fail to ground visual reasoning in the correct evidence. |
AuditDM for Model Improvement
| AuditDM also enables efficient, scalable synthesis of weakness-aligned training data. Once trained, the auditor can generate a tailored image–question pair from a single inference on any image. Training on this data yields significant gains across all tested benchmarks. |
BibTex